经济预测复习
复习经济预测技术
参考书:经济预测与决策技术 武汉大学出版社 第六版
经济预测的基本原理
经济预测的概念
1.什么是经济预测
经济预测是一门研究经济发展过程及其变动趋势的学科,它是综合运用哲学、社会学、经济学、统计学、数学以及系统工程和电子计算技术等学科的有关理论和方法,根据学科自身的逻辑性,对经济现象之间的联系以及作用机制作出科学分析,并对经济过程及其各要素的变动趋势做出客观描述,从而对未来的经济发展轨迹,做出科学的判断和预见。
2.经济预测与计划和决策之间的关系
经济预测和经济计划都是经济管理的重要组成部分,两者既有共同点,又有不同点。共同点是两者的工作对象都是未来的经济状态;不同点是前者仅是对未来经济状态的一种估计或陈述。后者说明的问题是,如果不进行任何经济、政策或行政手段的干预,未来将有什么样的变化,经济状态将会变成怎样。而经济决策的目标又是由经济预测的结果确定的。
预测的要素
数据要素、方法要素、分析要素、判断要素
经济预测的步骤
step1:确定预测目标的预测期限
step2:确定预测因子
step3:进行经济调查
step4:选择合适的预测方法
step5:对预测的结果进行分析和评估
step6:指出根据最新的经济动态和新到来的经济数据,可否重新调整原来的预测值,并提高预测精度
step7:写好预测报告
判断预测技术
头脑风暴法
1.头脑风暴法是通过一组专家共同开会讨论,进行信息交流和互相启发,从而诱发专家们发挥其创造性思维,促进他们产生“思维共振”,以达到互相补充,并产生“组合效应”的预测方法。
2.头脑风暴法有创业头脑风暴和质疑头脑风暴两种。
创业头脑风暴就是组织专家对所要解决的问题,开会讨论,各抒己见地、自由地发表意见,集思广益,解决所要提出问题的具体解决方案。
质疑头脑风暴就是对已制定的某种计划方案或工作文件,召开专家会议,由专家提出质疑,去掉不合理或不科学的部分,补充不具体或不全面的部分,使报告或计划趋于完善。
3.专家的选择要与预测的对象相一致,而且要有一些知识渊博,对问题理解较深的专家参加。
一般来说,要有以下几方面专家参加会议,即 方法论学者,也就是预测专家; “设想”产生者,也就是专业领域内的专家, 分析者,是指专业领域的高级专家, 演绎者,是指有较高推断思维能力的专家。
4.对头脑风暴法的评价
优点:
(1).通过信息交流,产生思维共振,进而激发创造型思维,能在短期内得到创造性的成果。
(2).通过头脑风暴会议,获取的信息量大,考虑的预测因素多,提供的方案也比较全面和广泛。
缺点:
(1).专家会议,易受权威的影响,不利于充分发表意见
(2).易受表达能力的影响
(3).易受心理因素的影响
(4).容易随大流
特尔斐(Delphi)法
1.特尔斐法的基本原理
特尔斐法的应用过程是由主持预测的机构确定课题并选定专家,人数多少视具体情况而定,一般为10-50人。 预测机构与专家联系的主要方式是函询,专家之间彼此匿名,不发生任何横向联系。通过函询收集专家意见,加以综合、整理后,再反馈给各位专家,征求意见。这样反复经过四至五轮,尽管每个专家发表的意见各有差异,但由于参与讨论的专家意见的人数较多,会出现一种趋于统计的稳定性,使专家意见趋于一致,作为最后预测的根据。
2.挑选专家的方法
这里所称的“专家”,是指对所要预测的目标比较了解,并有丰富的实践经验或较高的理论水平,对目标有一定见解的人。这些人既可以是教授、理论研究人员或者是工程师,也可以是有一定年龄的工人或管理人员。
3.专家意见的统计处理
通常采取中位数作为有代表性的预测值,把上、下四分位数作为有50%以上把握的预测区间。
4.对特尔斐法的评价
第一是匿名性,第二是反馈性,第三是收敛性。
趋势判断预测法
趋势判断的基本原理
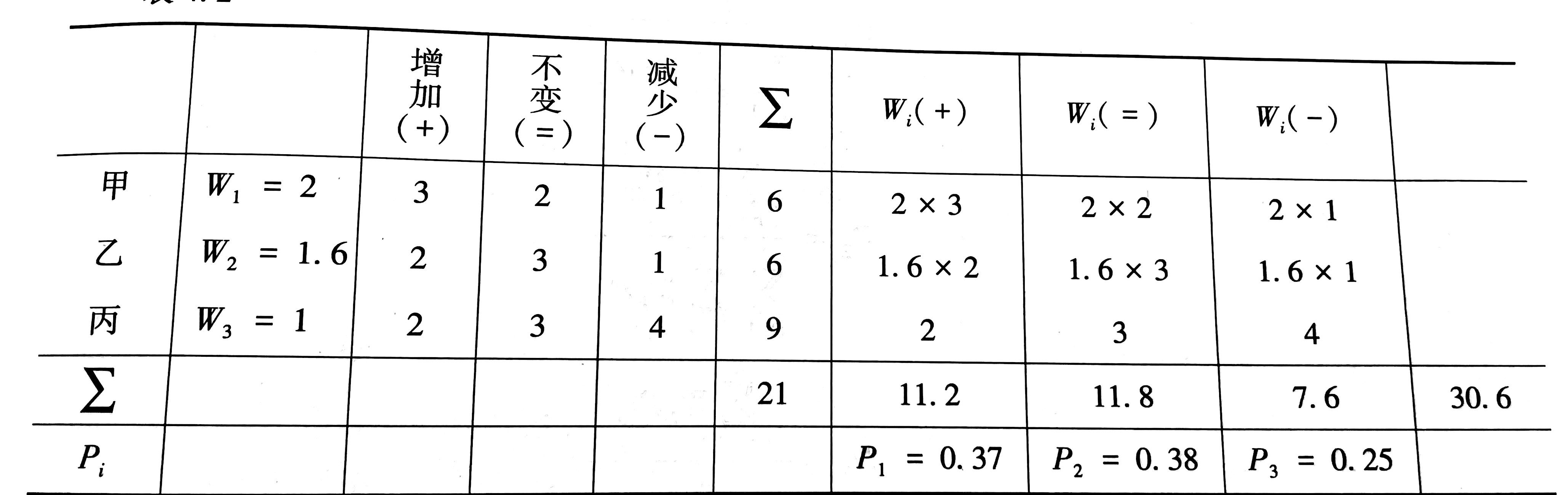
总共调查了$n=21$个厂,其中甲级厂$6$个,乙级厂$6$个,丙级厂$9$个,调查结果如下
其中甲级厂的销售额为$1000$万元,乙级厂$800$万元,丙级厂500万元,因此可选丙级厂做基准,令$W_3=1$,则$W_2=1.6$,$W_1=2$
其中$W$代表权重,若$P1-P3>0$则代表投资趋势为增加,$=0$则代表不变,$<0$则代表减少。
由下图可知,$P_1-P_3 = 0.12 > 0$
综合趋势判断
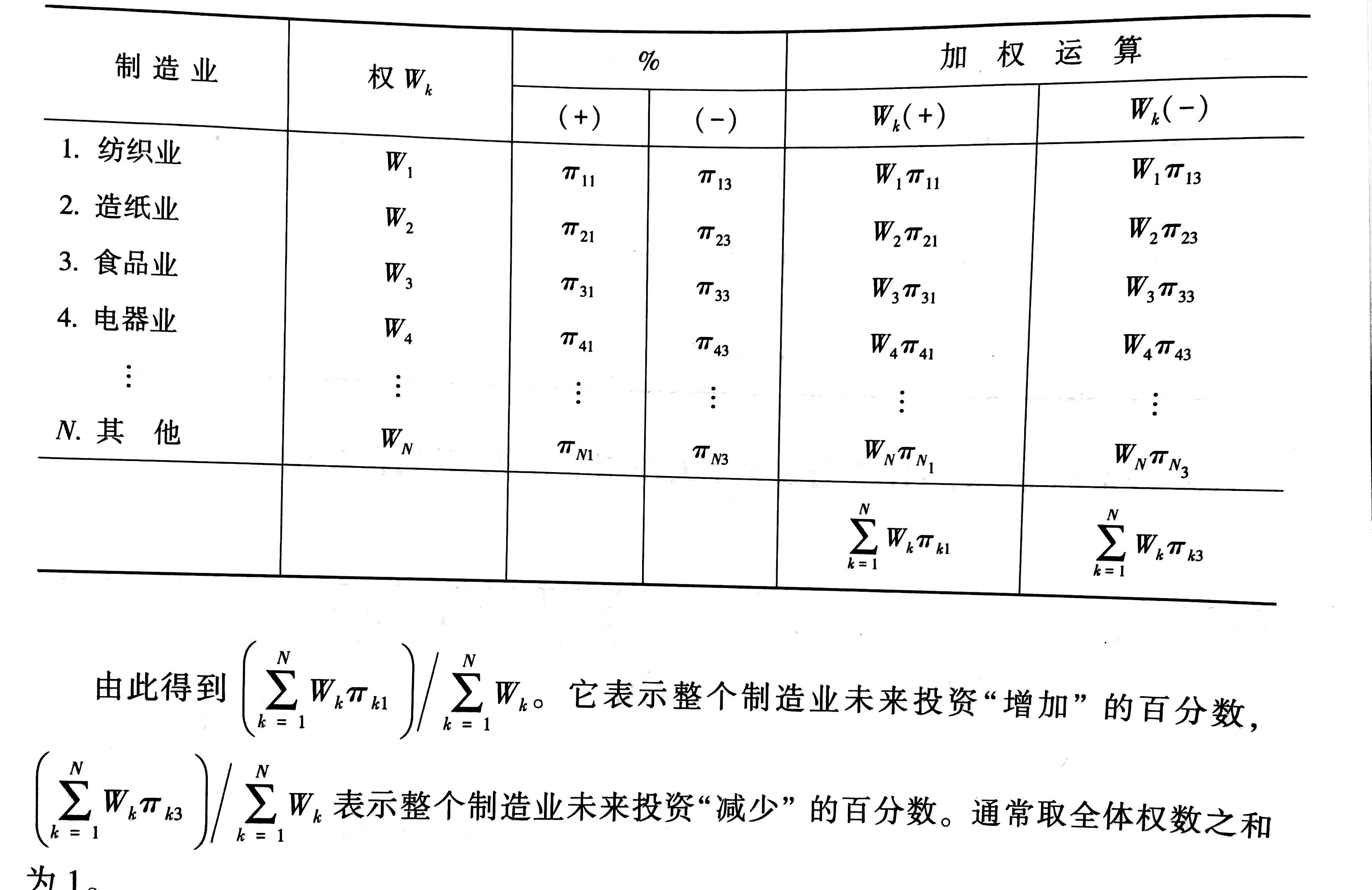
对于多行业的综合投资趋势预测,我们称为综合趋势判断。
假设在制造业中包含$N$个具体行业,对于某个具体的行业$k$,可按上面介绍的方法求出$P_1,P_2,P_3$,并作趋势判断。对于这$N$个具体行业,假定已按照上面的方法分别求出了$P_{ki}$

若$P_1-P_3>0$,则判断整个制造业未来投资将增加
若$P_1-P_3<0$,则判断整个制造业未来投资将减少
定量预测增加(减少)趋势的百分数
设甲级厂有$h$个厂未来投资将增加,$n$个厂未来投资将减少。增加、减少的百分数分别是$l_{11},l_{12},\cdots,l_{1h}$和$m_{11},m_{12},\cdots, m_{1n}$类似可调查乙厂、丙厂的 未来投资增加或减少的百分数。
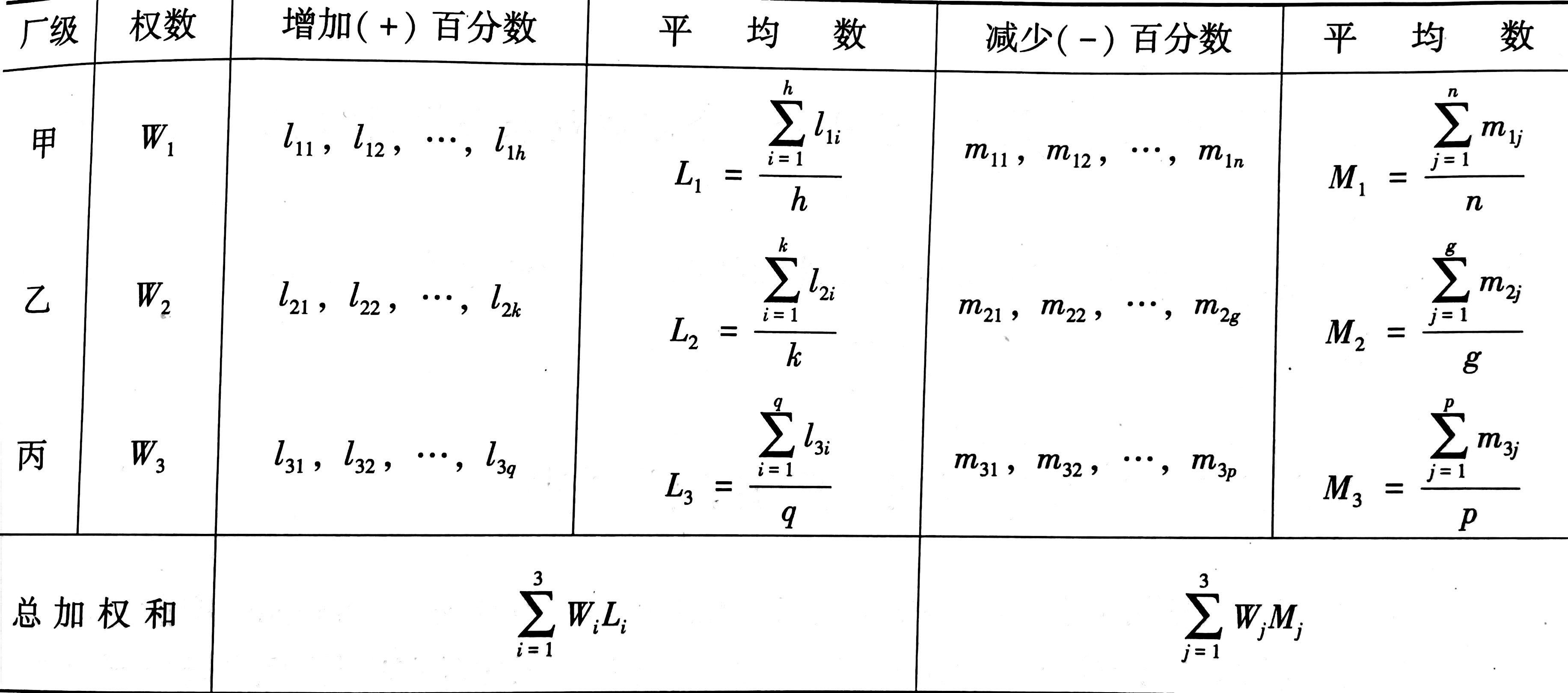
令
$$\frac{\sum_{i=1}^3W_iL_i}{\sum_{i=1}^3 W_i}=\pi_{k1} , \frac{\sum_{j=1}^3W_jL_j}{\sum_{j=1}^3 W_j}=\pi_{k3}$$
在这里,$\pi_{k1}$代表第$k$个行业认为未来投资会“增加”的百分数,$\pi_{k3}$则表示未来投资将会“减少”的百分数。
计算出各行业的增加和减少的百分数后,就可以对整个行业的总体投资趋势进行综合分析。
PERT预测法
假如某某百货公司从某种商品有销售人员3人和正、副经理2人,他们对下一季度的商品销售量分别作了如下估计:
| 最高销售量 | 最可能销售量 | 最低销售量 | |
|---|---|---|---|
| 甲 | 800 | 600 | 400 |
| 乙 | 900 | 700 | 500 |
| 丙 | 1000 | 800 | 480 |
我们可以用如下公式来求平均值和方差
$平均销售量=\frac{最高销售量+4\times 平均销售量 + 最低销售量}{6}$
$\sigma^2=\frac{(最高销售量-最低销售量)^2}{36}$
因此
| 平均销售量 | 标准差 | |
|---|---|---|
| 甲 | 600 | 66.7 |
| 乙 | 700 | 66.7 |
| 丙 | 780 | 86.7 |
则销售人员的预测为$(600+700+780)/3=693$件,标准差为$\frac{\sqrt{66.7^2+66.7^2+86.7^2}}{3} = 42.7$
如果有权重,例如$W_1=2,W_2=3,W_3=1$,则预测为$(600\times 2+700 \times 3+780)/6=680$,标准差为$\frac{\sqrt{4\times 66.7^2 + 9 \times 66.7^2 + 86.7^2}}{6} = 42.6$
销售人员判断预测综合法
现给出三个人员的预测结果
甲:最可能销售量为250单位,销售量在200-300单位之间的可能性为85%
乙:最可能销售量为200单位,销售量在160-240单位之间的可能性为90%
丙:最可能销售量为220单位,销售量在170-270单位之间的可能性为80%
假设销售量成正态分布,则有
对于甲来说:平均销售量为250单位,现来计算标准差
$2\Phi(\frac{300-250}{\sigma_甲})-1=0.85$,计算得$\Phi(\frac{50}{\sigma_甲}) = 0.925$
查表得$\frac{50}{\sigma_甲}=1.44$,于是$\sigma_甲=34.72$
计算出
甲的销售预测值得平均值为250单位,标准差为34.72
乙的销售预测值得平均值为200单位,标准差为24.24
丙的销售预测值的平均值为220单位,标准差为37.06
总的销售预测值为223.3单位,标准差为19.2
一元回归预测技术
简便求估方法
1.目估作图法
2.平均值法
精确求估方法
设回归方程为$\hat{y}=\hat{a}+\hat{b}x$
用$x_i$代替$x$就得到了$y_i$的预估值:$\hat{y_i}=\hat{a}+\hat{b}x_i$
残差为$e_i=y_i-\hat{y_i}$
令$Q=\sum_{i=1}^n e_i^2 = \sum_{i=1}^n (y_i-\hat{y_i})^2 = \sum_{i=1}^n (y_i-\hat{a} - \hat{b}x_i)^2$
使$Q$达到最小以估计$\hat{a},\hat{b}$的方法称为最小二乘法
对$\hat{a},\hat{b}$求偏导可知
$
\begin{cases}
\frac{\partial Q}{\partial \hat{a}}=-2 \sum\limits_{i=1}^n(y_i - \hat{a} - \hat{b}x_i)=0 \\
\frac{\partial Q}{\partial \hat{b}}=-2 \sum\limits_{i=1}^n(y_i - \hat{a} - \hat{b}x_i)x_i=0
\end{cases}
$
整理得
$
\begin{cases}
n\hat{a} +\hat{b} \sum\limits_{i=1}^n = \sum\limits_{i=1}^n y_i \\
(\sum\limits_{i=1}^n x_i) \hat{a} + \hat{b} \sum\limits_{i=1}^n x_i^2 = \sum\limits_{i=1}^n x_iy_i
\end{cases}
$
求解得
$
\begin{cases}
\hat{a} = \bar{y}-\hat{b}\bar{x} \\
\hat{b} = \frac{\sum\limits_{i=1}^n x_iy_i - \bar{x}\sum\limits_{i=1}^n y_i}{\sum\limits_{i=1}^n x_i^2 - \bar{x} \sum\limits_{i=1}^n x_i}
\end{cases}
$
可以证明$\hat{a},\hat{b},\hat{\sigma}^2=\frac{Q}{n-2}$是$a,b,\sigma^2$的无偏估计。
时间序列趋势外推预测
样本具有水平趋势的外推预测
1.朴素预测法:以本月销售量作为下月销售量的预测值
2.平均数预测法:将样本序列值$y_1,y_2,\cdots , y_k$做算术平均,以此作为$y_{k+1}$的预测值
样本具有非水平趋势的外推预测
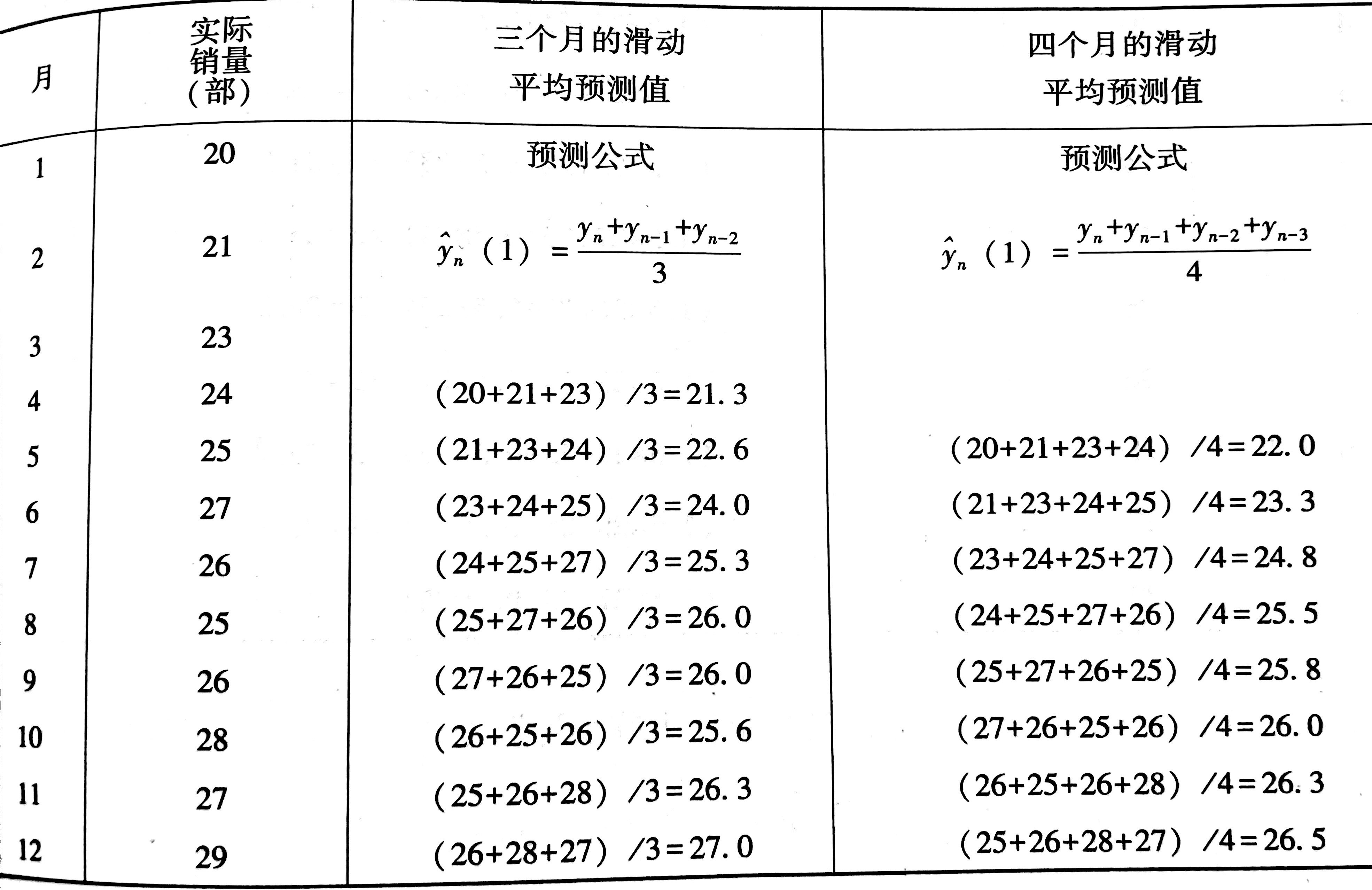
加权滑动平均法
用$ \hat{y_n} (1) $ 代表 $y_{n+1}$ 的预测值,滑动平均说的是
$$\hat{y_n}(1)=\frac{y_n+y_{n-1}+\cdots + y_{n-N+1}}{N}$$
$N$是滑动平均时段长
加权滑动平均说的是
$$\hat{y_n}(1)=\frac{\alpha_0 y_n+\alpha_1 y_{n-1}+\cdots + \alpha_{N-1}y_{n-N+1}}{N}$$
其中$\alpha_0,\cdots \alpha_{N-1}$为加权滑动因子,满足$\sum\limits_{i=0}^{N-1}\alpha_i = N$
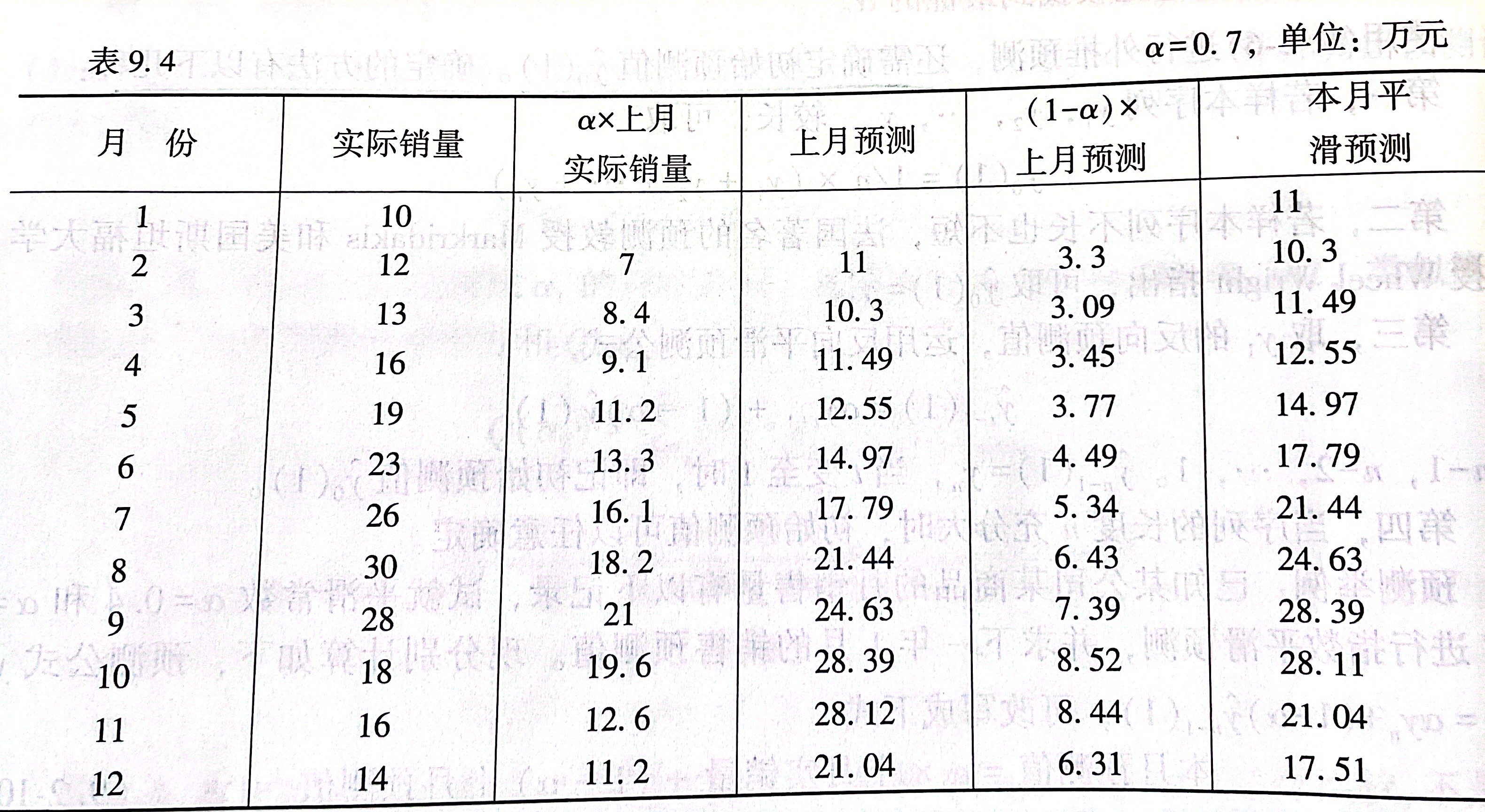
指数平滑预测法
$$\hat{y_n}(1) = \alpha y_n + (1-\alpha)\hat{y_{n-1}}(1) , 0 < \alpha < 1 $$
为使得误差平方和$Q(\alpha)=\sum_{t=1}^n(y_t - \hat{y_{t-1}}(1))^2$最小,需要合适的选取$\alpha$
如何选取$\alpha$?
1:穷举法
2:优选法(0.618法)
3:直观法,若序列变化较慢,则宜选取较小的$\alpha$,反之,若序列变化叫迅速,则应选取较大的$\alpha$
初始预测值如何确定?
1.样本序列较长,可取$\hat{y_0}(1)=1/n \times (y_1+\cdots + y_n)$
2.若样本序列不长也不短,可取$\hat{y_0}(1)=y_1$
3.取$y_1$的反向预测值,运用反向平滑预测公式$\hat{y_{t-1}}(1)=\alpha y_{t+1}+(1-\alpha)\hat{y_t}(1)$
4.当序列长度充分大时,可以任意确定
5.例题中,初始预测值选择了前两个月销售额的平均值
样本具有线性趋势的外推预测
设线性趋势方程为$y_t=a+b_t$,这里$a,b$是常数。
二次滑动平均值预测法
所谓二次滑动平均值,就是在一次滑动平均值再做一次滑动平均得到的值。
设一次滑动平均值为$\hat{y_t}$,两次滑动平均值为$\hat{\hat{y_t}}$,可以得到
$
\begin{cases}
b_t = 2(\hat{y_{t+1}} - \hat{\hat{y_{t+1}}})/(N+1) \\
a_t = 2\hat{y_{t+1}} - \hat{\hat{y_{t+1}}} - b_t
\end{cases}
$
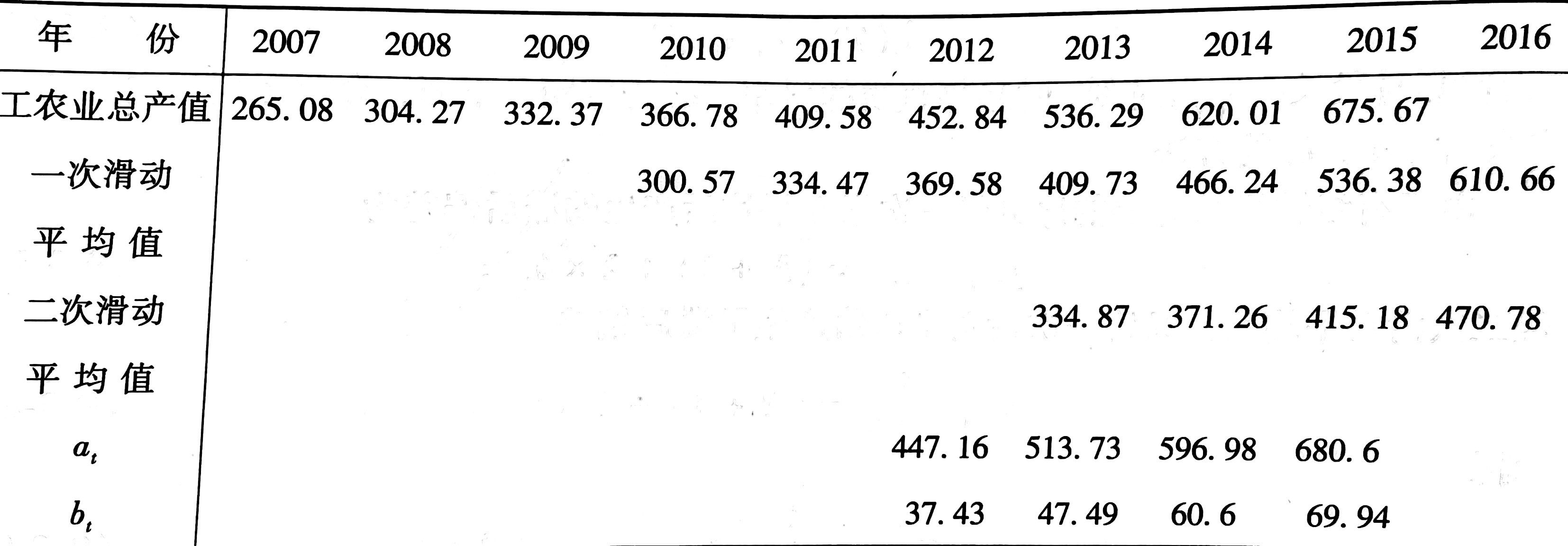
假设现在是2015年,我们要预测2017年的GDP,预测期$T=2$,那么有
$\hat{y_{2015}}(2)=680.6+69.94 \times 2=820.48$(亿元)
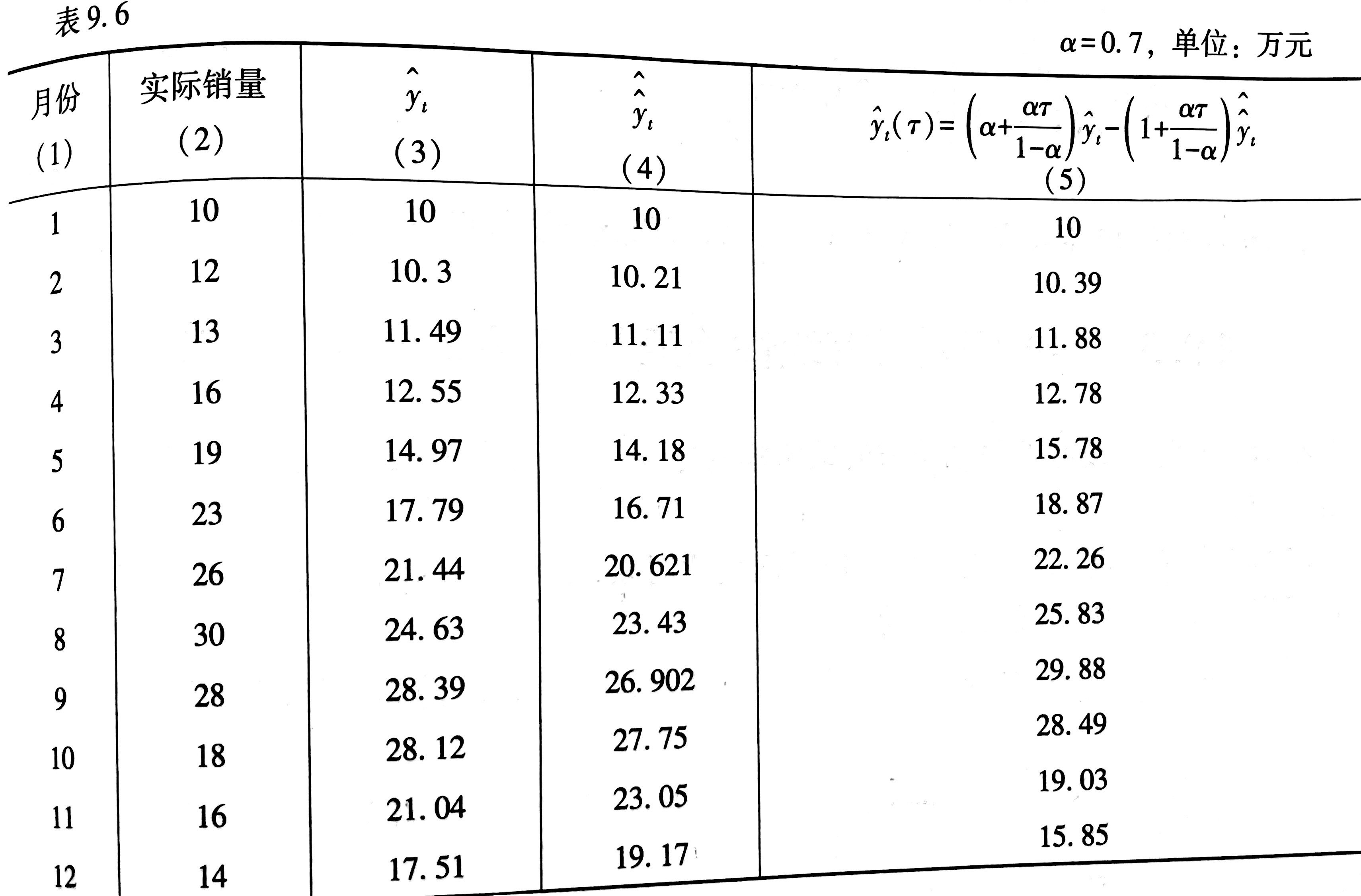
二次指数平滑预测
指对一次指数平滑后的序列数据再做一次指数平滑
$
\begin{cases}
b_t = \frac{\alpha}{1-\alpha} (\hat{y_t}-\hat{\hat{y_t}}) \\
a_t = 2\hat{y_{t}} - \hat{\hat{y_{t}}}
\end{cases}
$
样本具有二次曲线趋势的外推预测
二次曲线趋势可以写成$\hat{y_{t+\tau}’} = a_t + b_t \tau + c_t \tau^2$,其中$\tau$为预测期
可以采用三次指数平滑方法确定参数,也可使用三和法确定参数
样本具有线性趋势和季节波动的外推预测
假定时间序列受以下因素影响:
1.趋势变化因素:当时间序列依时间变化时出现某种倾向,按某种规律稳步增长或下降或在某一水平线上上下波动
2.季节变化因素:这是一种周期性变化因素的影响,这种周期时固定的,例如一年四季
3.随机因素影响:它是由许多不可控制的因素影响而引起的变化,这种周期是固定的,例如一年四季。
时间序列$y_t$的结构有以下三种模式:
1.加法模式$y_t=T_t+S_t+\epsilon_t$
这里要求满足条件:
(1):$y_t,T_t,S_t,\epsilon_t$具有相同的量纲
(2):$\sum_{t=1}^k S_t = 0$,$k$为季节周长,例如$k=4$或者$k=12$
(3):$\epsilon_t$是独立的随机序列,服从$N(0,\sigma^2)$
2.乘法模式$y_t=T_tS_te^{\epsilon_t}$
这里要求满足条件:
(1):$y_t$和$T_t$有相同的量纲,$S_t$是季节指数,$S_t>0$是比例数
(2):$\sum_{t=1}^kS_t=k$,例如$k=4,\sum_{t=1}^4 S_t=4$
(3):$\epsilon_t$是独立的随机变量序列,服从$N(0,\sigma^2)$
3.混合模式$y_t = T_tS_t+\epsilon_t$
这里要求满足条件:
(1):$y_t$与$T_t,\epsilon_t$有相同的量纲,$S_t$是季节指数,是比例数
(2):$\sum_{t=1}^kS_t=k$,例如$k=4,\sum_{t=1}^4 S_t=4$
(3):$\epsilon_t$是独立的随机变量序列,服从$N(0,\sigma^2)$
加法型序列的趋势外推预测法
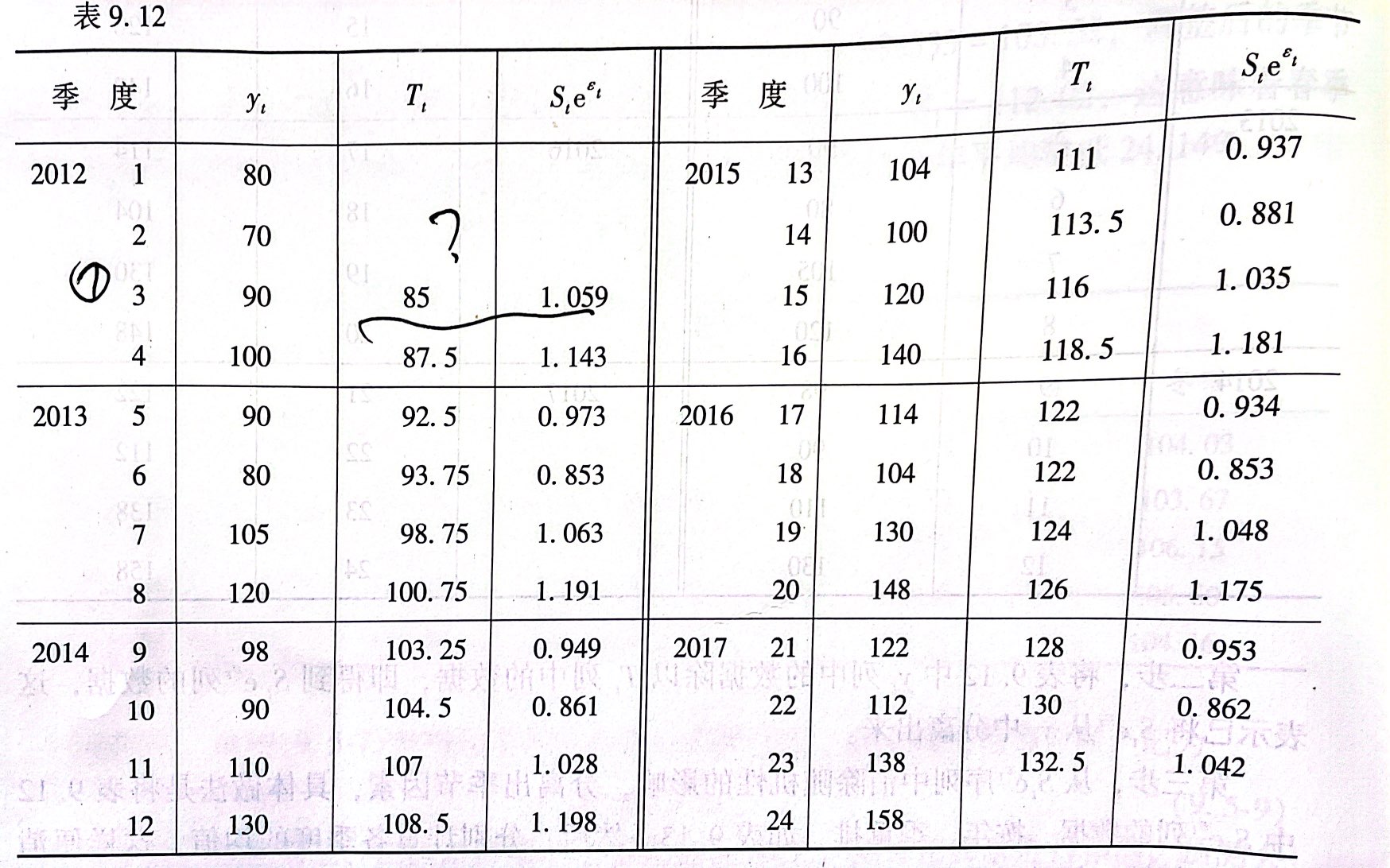
假设样本序列为$y_1,y_2,\cdots, y_n$,序列$y_t$是加法型,即$y_t=T_t+S_t+\epsilon_t$,季节长度为4,$T_t$具有线性趋势,$S_1,S_2,S_3,S_4$为季节分量,满足$\sum_{i=1}^4 S_i=0, S_i = S_{i+4t}$,$\epsilon_t$服从$N(0,\sigma^2)$,求$y_n+T$的预测值,预测步骤如下
step1:对样本做长度为3的滑动平均,削去随机干扰,记滑动平均后的序列为$\bar{y_t}$
step2:对$\hat{y_t}$,求出趋势线$\hat{T_t}=a+bt$,这一步可以用一元回归的简便/精确求估方法得到
step3:将序列$y_t$消除趋势因素的影响,求出消去趋势线后的序列值$M_t=y_t-\hat{T_t}$
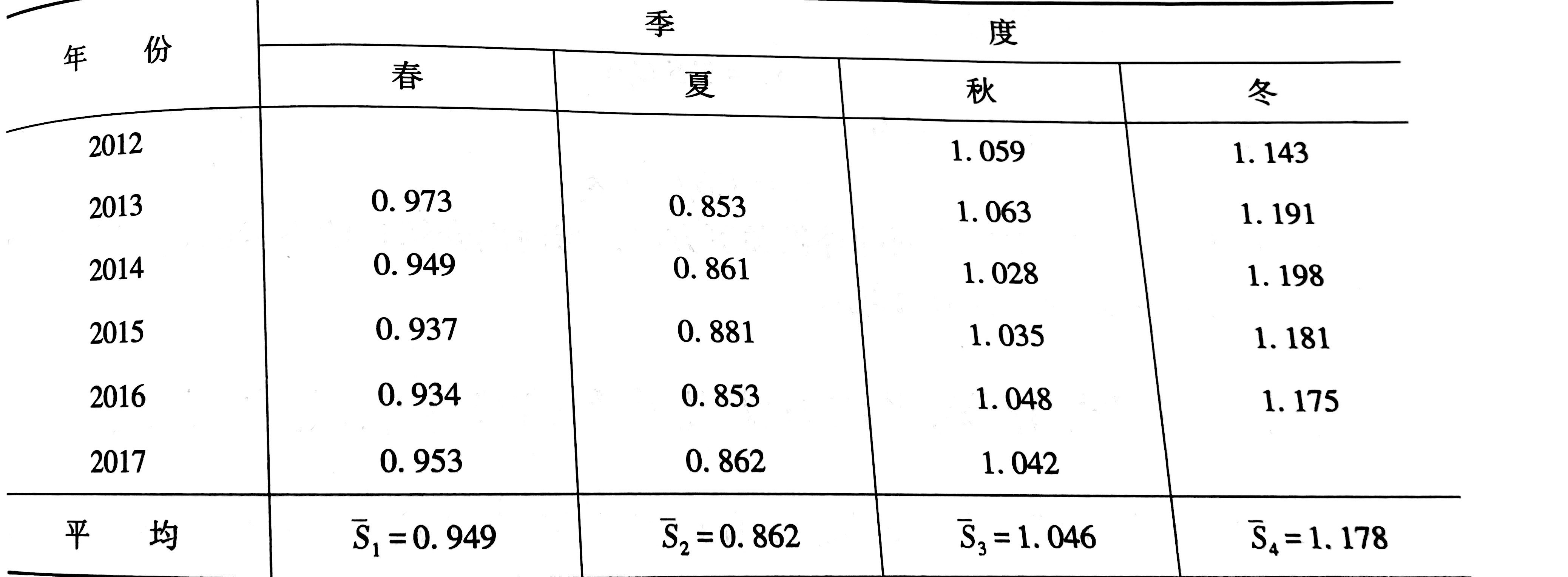
step4:将$M_t$按照季节次序重排,对每个季度的$M_t$算出平均值,依次记为$\bar{S_1},\bar{S_2},\bar{S_3},\bar{S_4}$,分别为样本序列的季节指数
step5:对样本季节指数进行检验,若$\sum_{i=1}^4 \bar{S_i}=0$,则符合季节指数的条件,否则进行修正,修正公式为:$S_i = \bar{S_i} - \frac{\sum_{i=1}^4 \bar{S_i}}{4}$。
step6:运用已求得的$T_t,S_t$即可进行预测,由于$\epsilon_t$是不可预测的随机干扰,由此得到$\hat{y_{n+T}}=\hat{T_{n+T}}+S_{n+T} = [a+b(n+T)] +S_{n+T} = [a+b(n+T)] +S_{i+4n} = [a+b(n+T)] +S_{i}$
乘法型序列的趋势外推预测法
设$y_t=T_t \times S_t \times e^{\epsilon_t}$,样本序列为$y_1,y_2,\cdots, y_n$
step1:对$y_t$序列值分解出长期因素,假设季节长度为4,只要将序列做滑动长度为4的滑动平均,即可消除随机干扰和季节波动的影响。记滑动平均值为$MAy_t = (y_t+y_{t-1} + y_{t-2} + y_{t-3})/4 $
step2:对$y_t$分解出季节因素与随机因素,用$MAy_t$去除$y_t$,得到$ \frac{y_t}{MAy_t} = \frac{T_t\times S_t \times e^{\epsilon_t}}{T_t} = S_t e^\epsilon_t$
step3:从$S_te^{\epsilon_t}$中分解出季节因素$S_t$,将$S_t e^{\epsilon_t}$ 按照春夏秋冬重排,将所有季节指数相加求平均值,得到$\bar{S_1},\bar{S_2},\bar{S_3},\bar{S_4}$,若与标准季节指数$\sum_{i=1}^4S_i=400$有差异,则进行修正,修正公式为:$S_i=\bar{S_i} \times \frac{\sum_{i=1}^4 {S_i}}{\sum_{i=1}^4 \bar{S_i}}$
step4:利用滑动平均所得到的序列建立线性趋势方程,记为$\hat{T_t} = \hat{a}+\hat{b}t$
step5:根据step3,4所得到的季节指数$S_t,T_t$,按要求进行预测,公式为
$\hat{y_{n+T}} = \hat{T_{n+T}}\bar{S_{i+4m}}=\hat{T_{n+T}}\bar{S_{i}}$
考虑循环因素影响有线性趋势和季节波动的时间序列模型
1.加法型:$y_t=T_t+S_t+C_t+\epsilon_t$
2.乘法型:$y_t=T_tS_tC_te^{\epsilon_t}$
3.混合型:$y_t=T_tS_tC_t+\epsilon_t$
注记:三和法和三点法
所谓三和法就是将整个增长序列分为三个相等的时间周期,并对每一个时间周期的数据求和以估计参数,估计参数的方法是求解方程组
所谓三点法就是假定曲线通过已知的三个点,即增长序列的始点,中间点和终点。同时,要求相邻两点时间距离相等,即$t=0,n,2n$。
马尔科夫决策
基本概念
转移概率矩阵$P=(p_{ij})_{n\times n}$ , $p_{ij}$表示从状态$i$转移到状态$j$的概率
转移概率矩阵有如下性质:
(1):$p_{ij} \ge 0$,即每个元素是非负的
(2):$\sum_{j=1}^N p_{ij}=1,i=1,2,\cdots,n$即矩阵的每行元素和为1
经过$n$步转移,在时刻$t_n$时处于$j$,这种转移的可能性的数量指标称为$n$步转移概率,记为$P(x_n=j|x_0=i)=p_{ij}(n)$,并记$P(n)=P^n$为$n$步转移矩阵。
$n$步转移矩阵同$1$步转移概率一样有上述两个性质,性质(1)是显然的,性质(2)可以用归纳法证明
状态转移概率的估算
有销售状态数据如下:

上表中有24个季度数据,其中有14个季度畅销,9个季度滞销,其中最后一个季度没有下个季度的新消息,故不考虑。
其中由畅销转畅销有$7$个季度,由畅销转滞销有$7$个季度,其中由滞销转畅销有$7$个季度,其中由滞销转滞销有$2$个季度
则状态转移矩阵可写为$P=\begin{pmatrix}0.5 & 0.5 \\0.78 & 0.22 \\ \end{pmatrix} $
带利润的马尔科夫链
$n$步转移利润为$v_i(n)=\sum_{j=1}^n (r_{ij}+v_j(n-1))p_{ij}$,其中$n=1$时,$v_j(0)=0$
称一步转移的期望利润为即时的期望利润,并记$v_i(1)=q_i$
市场占有率预测
设初始状态为$c$,则$k$步转移后的状态为$c(k)=c^T P^k$
所谓稳定的市场平衡状态,就是满足$
\begin{cases}
X = PX \\
\sum X = 1
\end{cases}
$的向量$X$
景气预测与预警系统
景气循环的基本概念
1.景气是对经济发展状况的一种综合性描述,用以说明经济活跃程度的概念。所谓经济景气,是指总体经济呈上升发展趋势,呈现出市场繁荣,购销两旺的景气状态。经济不景气是指总体经济呈下滑的发展趋势,绝大部分经济活动处于收缩或半收缩状态,表现出市场疲软,经济效益下降,许多企业破产倒闭,失业人数增加等现象。
2.景气循环又称经济波动,是指经济活动高潮与低潮时期的相互交替。一般说来,景气上升阶段,生产、就业、投资、物价、利润都向上发展,市场上购销两旺。景气下降阶段则相反,表现为增长率下降,失业和企业倒闭增加,在市场上出现销售疲软,经济效益下降。
景气循环通常分为四个阶段,具体为:复苏期、扩张期、收缩期、萧条期
扩散指数DI的编制与应用
step1:选取景气指标
step2:确定各被选指标在各时期的扩张或收缩
step3:求出扩散指数DI
step4:绘制出扩散指数变化图
综合指数CI的编制
step1:求出单个指标的对称变化率
step2:求标准化的平均变化率
step3:求初始综合指标
step4:求趋势调整
step5:求综合指数CI
随机事件序列的线性模型
随机序列线性模型的基本形式
自回归模型
序列值可以表示成它的先前值和一个冲击值$a_t$的线性函数
$y_t = \varphi_1y_{t-1}+\varphi_2y_{t-2}+\cdots + \varphi_p y_{t-p}+a_t$ ,记为$AR(p)$
令$B$为后移算子
$By_t=y_t-1,BC=C$
$B^my_t = y_{t-m} , B^mC=C$
则$AR(p)$模型可以写为$(1-\varphi_1B-\varphi_2B^2+\cdots - \varphi_pB^p)y_t=a_t$
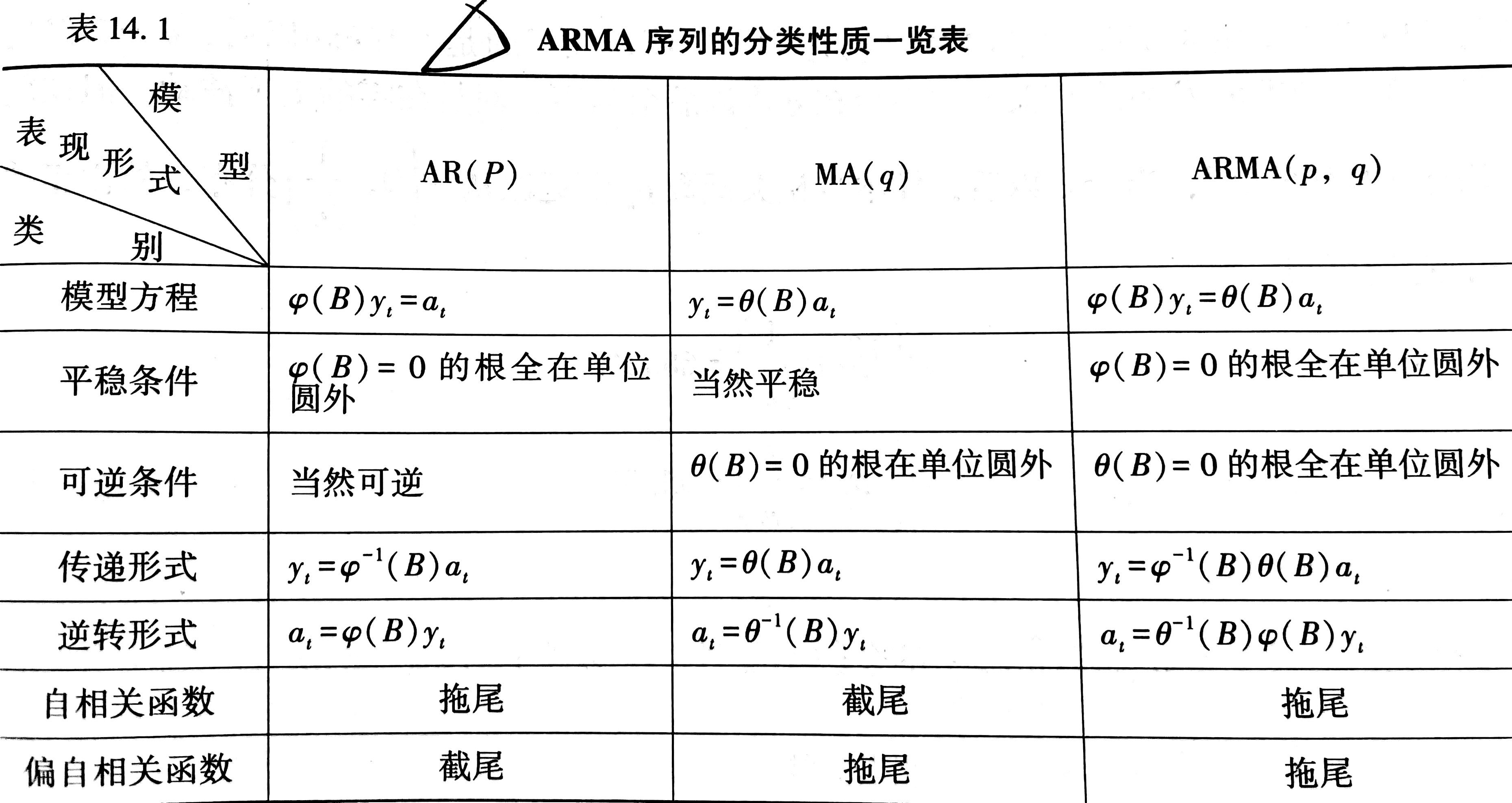
记$(1-\varphi_1B-\varphi_2B^2+\cdots - \varphi_pB^p) = \varphi(B)$,则$AR(p)$模型可以写为$\varphi(B)y_t=a_t$
平稳性条件是$\varphi(B)=0$的根全在单位圆外,并且其一定可逆
本身就是逆转形式,传递形式为$y_t=\varphi^{-1}(B)a_t$
滑动平均模型
序列值是现在和过去的误差或冲击值$a_t$的线性组合
$y_t=a_t-\theta_1a_{t-1}-\theta_2a_{t-2}-\cdots - \theta_q a_{t-q}$,记为$MA(q)$
使用后移算子符号,可以写成$y_t=(1-\theta_1B-\theta_2B^2-\cdots -\theta_qB^q)a_t$
记$(1-\theta_1B-\theta_2B^2-\cdots -\theta_qB^q)=\theta(B)$,则$MA(q)$模型可以写为$y_t=\theta(B)a_t$
可逆性条件是$\theta(B)=0$的根全在单位圆外,并且其一定平稳
本身就是传递形式,逆转形式为$\theta^{-1}(B)a_t=y_t$
自回归滑动平均模型
序列值$y_t$是现在和过去的误差或冲击值$a_t$以及先前的序列值的线性组合
$y_t=\varphi_1y_{t-1}+\varphi_2y_{t-2}+\cdots + \varphi_p y_{t-p} +a_t - \theta_1a_{t-1}-\theta_2a_{t-2}-\cdots - \theta_q a_{t-q}$
又可以写为$\varphi(B)y_t=\theta(B)a_t$,记作$ARMA(p,q)$
平稳可逆的条件是$\varphi(B)=0$和$\theta(B)=0$的根全在单位圆外。
传递形式为$y_t=\varphi^{-1}(B)\theta(B)a_t$,逆转形式为$a_t=\theta^{-1}(B)\varphi(B)y_t$
非平稳序列的平稳化方法
消除趋势的方法
进行$d$阶差分,之后的模型记为$ARIMA(p,d,q)$模型
消除季节影响
通过季节差分,可以消除季节影响。若季节长度为$S$,序列值为$Z_t$,则一阶季节差分可以写为$\nabla_S Z_t = Z_t - Z_{t-s}$,高阶的可以类比
消除不平稳方差
可以采用对数变换$y_t=lgZ_t$或者开平方根$y_t=\sqrt{Z_t}$
季节模型
季节自回归模型
$y_t=\Phi_1y_{t-s}+a_t$,称为一阶季节自回归模型,简记为$SAR(1)$模型
一般的自回归模型,可以写为$\Phi(B^s)W_t=a_t$
其中$\Phi(B^s)=1-\Phi_1B^s-\Phi_2B^{2s}- \cdots - \Phi_pB^{ps}$
$W_t = \nabla_s^D \nabla^d {y_t}$
其中$\nabla^d$为$d$阶连续差分,$\nabla_s^D$为$D$阶季节差分,$S$为季节跨度长。
季节滑动平均模型
$y_t=a_t-\Theta_1a_{t-s}$,称为一阶季节滑动平均模型,简记为$SMA(1)$
一般的滑动平均模型,可以写为$W_t=\Theta(B^s)a_t$
其中$\Theta(B^s)=1-\Theta_1B^s-\Theta_2B^{2s} - \cdots - \Theta_QB^{Qs}$
$W_t = \nabla_s^D \nabla^d {y_t}$
季节自回归混合滑动平均模型
$\Phi(B^s)W_t=\Theta(B^s)a_t$
其中
$\Phi(B^s)=1-\Phi_1B^s-\Phi_2B^{2s}- \cdots - \Phi_pB^{ps}$
$\Theta(B^s)=1-\Theta_1B^s-\Theta_2B^{2s} - \cdots - \Theta_QB^{Qs}$
$W_t = \nabla_s^D \nabla^d {y_t}$
简记上述模型为$ARMA(P,D,Q)$,这里
$P$为季节自回归过程的阶数
$Q$为季节滑动平均过程的阶数
$D$为季节差分的阶数
$S$为季节跨度长
随机事件序列模型的识别
自相关函数
$AR(p)$的自相关函数
首先研究$AR(1)$模型,设$y_t=\varphi_1y_{t-1}+a_t$,它的自协方差函数为
$r_1=Ey_ty_{t-1}=E(\varphi_1y_{t-1}+a_t)y_{t-1}=\varphi_1Ey_{t-1}^2 + Ea_ty_{t-1} = \varphi_1r_0$
$r_2=Ey_ty_{t-2}=E(\varphi_1y_{t-1}+a_t)y_{t-2}=E(\varphi_1(\varphi_1y_{t-2} + a_{t-1})+a_t)y_{t-2} = \varphi_1^2 r_0$
同理可得$r_k=\varphi_1^kr_0$,$\rho_k=\varphi_1^k$,即当$|\varphi|<1$时,$\rho_k \rightarrow 0$,但是不等于$0$,这种现象称为拖尾。
对于更一般的情形,可以从Yule Walker方程得到。
$MA(q)$的自相关函数
设$MA(q)$序列$y_t$的模型方程为$y_t=a_t-\theta_1a_{t-1}-\theta_2a_{t-2}-\cdots - \theta_q a_{t-q}$
则他的自协方差函数为
$r_k=Ey_{t+k}y_k=E(a_{t+k}-\theta_1 a_{t+k-1} - \theta_2 a_{t+k-2} - \cdots - \theta_{q} a_{t+k-q})(a_t - \theta_1 a_{t-1} - \cdots - \theta_q a_{t-q})$
由于$Ea_t=0,Ea_{t+j}a_t=\begin{cases}
0 & j\ne 0\\
\sigma_a^2 & j=0
\end{cases}$
所以$r_0=\sigma_a^2(1+\theta_1^2 + \theta_2^2 + \cdots + \theta_q^2)$
$r_k=0, k>q$
$r_k=\sigma_a^2(-\theta_k+\theta_1 \theta_{k+1} + \cdots + \theta_{q-k}\theta_q) , 0<k\le q$
$$\rho_k = \begin{cases}
1 & k=0\\
\frac{-\theta_k + \theta_1\theta_k+1 + \cdots + \theta_{q-k}\theta_q}{1+\theta_1^2 + \cdots + \theta_q^2} & 1\le k \le q
0 & k>q
\end{cases}$$
可见:$k>q$时,$\rho_k =0$,即$y_t$和$y_{t+k}$不相关,这种现象称为截尾。